Designing Data Intensive Applications...A Summary Part 1
— Software, Data, Backend, Architecture — 4 min read

If you are one of those guys that like cosmology like me, then probably you have seen this popular picture of our deep space.
And If you are a really nerdy cosmology guy then you know this picture is called The Pillars Of Creation and this is simply created from different gases, but in software we have different pillars of writing good software.
These 3 Pillars are what we should consider when thinking about writing and designing our applications and as simple as this might sound but it is most of the time extremely difficult to maintain a high level of those pillars.
The 3 Pillars of Software:
As Described by Martin Kleppmann in the first chapter of his book that you probably have already guessed from the blog title, Martin , talks about the 3 pillars of good software which are :
- Reliability 💻
- Scalability 🚀
- Maintainability 🔍
Reliability 💻
"Hey Siri Play me some music" music playing in the background
Just as simple as this interaction we have demonstrated what reliability means . It just means that the software is performing what is expected.
When something goes wrong and the software still runs correctly it means that it is reliable and resilient,the things that can go wrong are called faults, and systems that anticipate faults and can cope with them are called fault-tolerant.
We can classify these faults into 3 main categories:
- Hardware Faults ❌
- Software Bugs 🐞
- Human Errors 👨
Hardware Faults ❌ :
When we think of causes of system failure, hardware faults quickly come to mind. Hard disks crash, RAM becomes faulty, the power grid has a blackout, someone unplugs the wrong network cable. Anyone who has worked with large datacenters can tell you that these things happen all the time when you have a lot of machines. These types of hardware faults are easily fixed in today's world.
Software Bugs 🐞 :
Software Bugs are systematic errors inside the system. Examples can include:
- A service that the system depends on that slows down, becomes unresponsive, or starts returning corrupted responses.
- Cascading failures, where a small fault in one component triggers a fault in another component, which in turn triggers further faults.
Human Errors 👨 :
Study of large internet services found that configuration errors by operators were the leading cause of outages, whereas hard‐ ware faults (servers or network) played a role in only 10–25% of outages.
There are several ways to mitigate this from happening or reduce the impact if it happens , solutions may include :
Allow quick and easy recovery from human errors, to minimize the impact in the case of a failure.
Set up detailed and clear monitoring, such as performance metrics and error rates known as telemetry data.
In a nutshell reliability is a pretty important aspect because even if it is not a critical application, it can cost the company's reputation and loss of trust between customers.
Scalability ..To the moon 🚀🌑
Even if a system is working reliably today, that doesn’t mean it will necessarily work reliably in the future. One common reason for degradation is increased load.
Scalability is the term we use to describe a system’s ability to cope with increased load.
Describing Load:
Giving Context about what do we mean here by load can change differently talking about different software applications.
A Load can be depending on the application:
- Requests per second.
- The ratio of reads to writes on database.
- Simaltenously active users.
- Hit rate on cache.
Describing Performance:
Once you have described the load on your system, you can investigate what happens when the load increases. You can look at it in two ways:
When you increase a load parameter and keep the system resources (CPU, memory, network bandwidth, etc.) unchanged, how is the performance of your system affected?
When you increase a load parameter, how much do you need to increase the resources if you want to keep performance unchanged?
Let's run down a real example here:
If our application takes 1000 requests and the average resposne time is 200ms that is the average of taking the sum of all requests response time and dividing by the number of requests then we might say we have figured out what is our current application performance.
An average doesn't always give the best context of whether our application is performing good or bad why you might ask ?
Well because it doesn't tell how many users actually experienced the delay.
A better approach would be to speak in terms of percentiles. If you take your list of response times and sort it from fastest to slowest, then the median is the halfway point: for example, if your median response time is 200 ms, that means half your requests return in less than 200 ms, and half your requests take longer than that. This makes the median a good metric if you want to know how long users typically have to wait: half of user requests are served in less than the median response time, and the other half take longer than the median.
Maintainability 🔍
One of the most daunting tasks of a software engineer is maintaining applications or so called legacy systems because it envolves refactoring, fixing bugs and solving problems that you may have in any shape or form contributed to in the first place.
Refactoring also means that you need to touch on code that may have not been touched for years.
It is also well known that the majority of the cost of software is not in its initial development, but in its ongoing maintenance—fixing bugs, keeping its systems operational, investigating failures, adapting it to new platforms, modifying it for new use cases, repaying technical debt, and adding new features.
we can and should design software in such a way that it will hopefully minimize pain during maintenance, and thus avoid creating legacy software ourselves. To this end, we will pay particular attention to three design principles for software systems:
Operability:
Make it easy for operations teams to keep the system running smoothly.
Simplicity:
Make it easy for new engineers to understand the system, by removing as much complexity as possible from the system. (Note this is not the same as simplicity of the user interface.
Evolvability:
Make it easy for engineers to make changes to the system in the future, adapting it for unanticipated use cases as requirements change. Also known as extensibil‐ ity, modifiability, or plasticity.
Summary
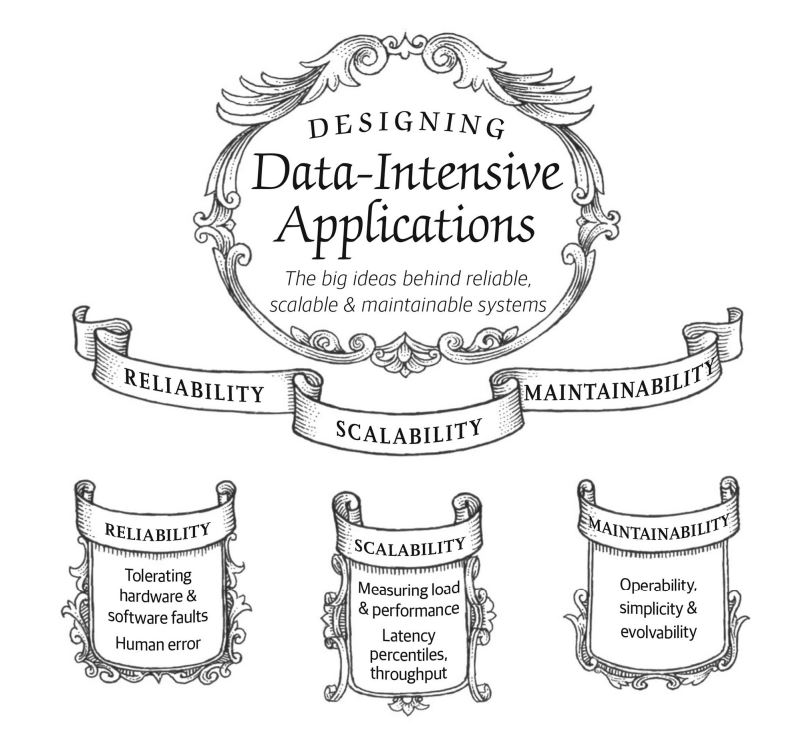
In Summary:
Reliability means making systems work correctly, even when faults occur. Faults can be in hardware (typically random and uncorrelated), software (bugs are typically systematic and hard to deal with), and humans (who inevitably make mistakes from time to time). Fault-tolerance techniques can hide certain types of faults from the end user.
Scalability means having strategies for keeping performance good, even when load increases.
Maintainability is about making life better for the engineering and operations teams who need to work with the system. Good abstractions can help reduce complexity and make the system easier to modify and adapt for new use cases.
Reference : Designing Data Intensive Applications
ARIGATO GOZAIMASU ありがと ございます