Reliable Message Processing Techniques in Kafka
— Software, Message Queue, Kafka, Architecture — 3 min read
Reliable Message Processing
One of the most challenging parts of writing software is that software being resilient and ensuring that when there are some transient errors that the system is able to gracefully recover and ensure that the unit of work that the software is doing is eventually going to be delivered.
In this Blog Spot we are going to discuss about if you have 2 systems that are communicating together through messaging and one goes down , how do you ensure that all messages are going to be "Eventaully" sent without the messages being lost in the transient errors.
Now that we know the problem definition let's talk about some of the proposed solutions that you might think of as a brute force solution to this kind problem.
Solution Approach 1:
You might think oh since that we assume that this is a transient error why not implement a retry mechanism and one would be a simple retry mechanism let's assume the following diagram:
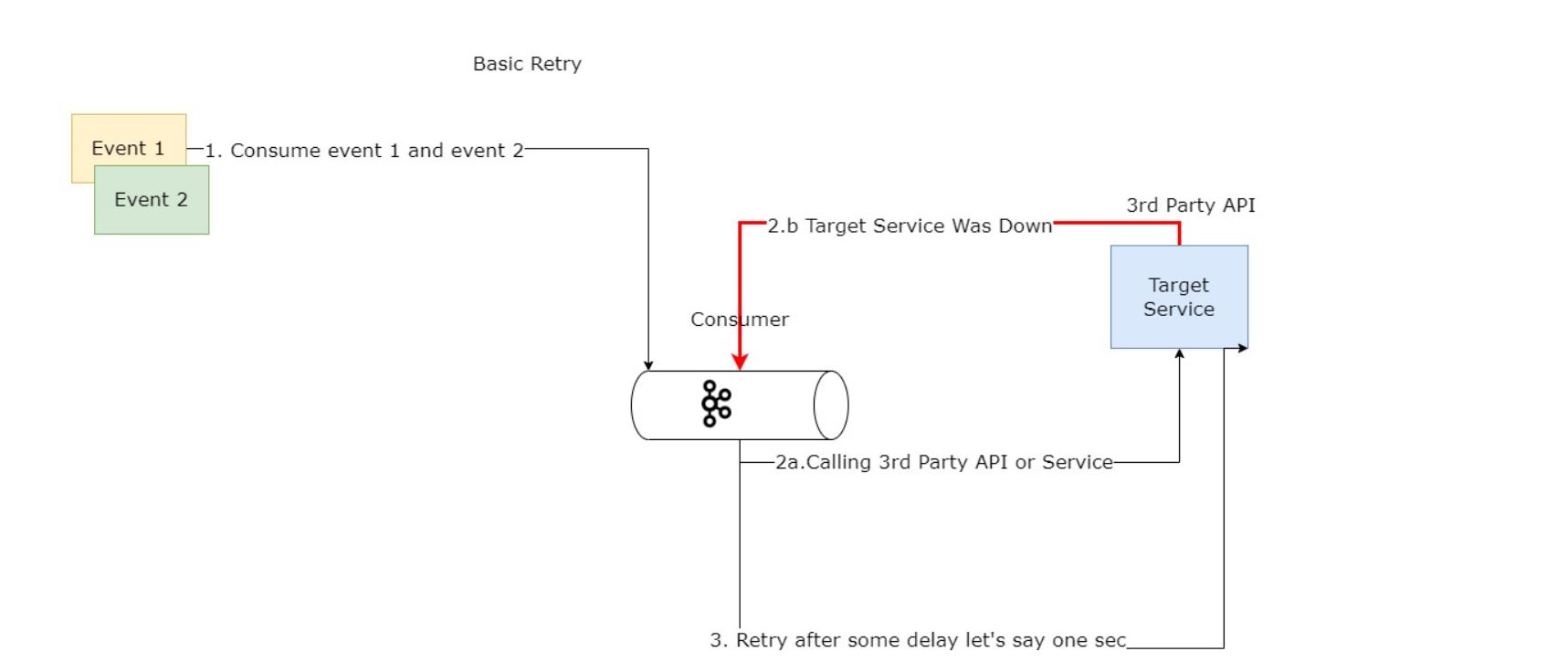
While this approach provides a simple solution and might solve the problem but it has a few drawbacks:
- If there are messages being sent after , then this approach will block the other messages until the retry flow is done.
- This simple retry mechanism will work only once and the message then is then lost after.
To solve problem no. 2 we can add some application logic to have some retry count , for example you can try to retry for example 5 times.
In an application that might scale and processing a lot of messages at the same time where blocking the messages is not an option then this solution will not work or fit the business needs.
Onwards to Solution Approach 2 :
Let's introduce a solution that will solve the main problem that we had in approach no. 1 which is blocked processing of messages. In this Proposed diagram below we address the problem of blocked batches by retrying in separate queues with separate topics.
if a consumer handler returns a failed response for any (transient) reason, the consumer publishes this message to it's corresponding retry topic to be handled separately.
The handler then returns true to its original consumer and in return this leads to committing the offset.
Retrying requests in this type of system is as follows:
As with the main processing flow, a separate group of retry consumers will read off their corresponding retry queue.
- These consumers behave like those in the original architecture, except that they consume from a different Kafka topic.
- Executing multiple retries is accomplished by creating multiple topics, with a different set of listeners subscribed to each retry topic.
- When the handler of a particular topic returns an error response for a given message, it will publish that message to the next retry topic below it as diagram below.
- Finally, the DLQ is defined as the end-of-the-line Kafka topic in this design. If a consumer of the last retry topic still does not return success, then it will publish that message to the dead letter topic. From there, a number of techniques can be employed for listing, purging, and merging from the topic.

Final Arhcitecture diagram
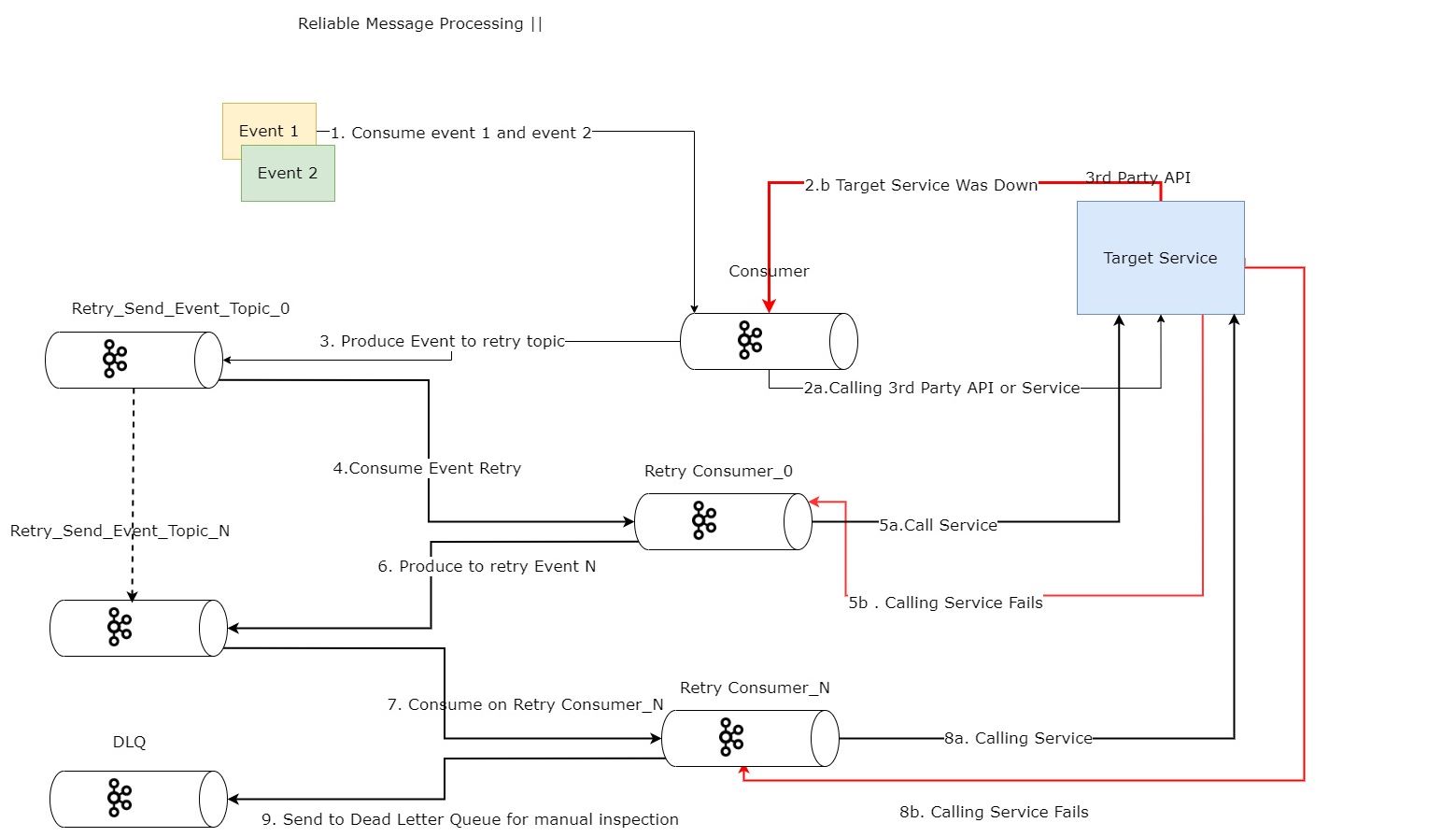
let's break this diagram down :
- we try to send a message.
- the consumer recieves the message and tries to call 3rd party services 3.the 3rd party service fails
- it tries to then send the message to the retry topic after some configurable time.
- the process continues in the same fashion until the message is delivered and the service is up.
- if service is down then finally the message is sent to a dead letter topic for manual inspection and for the developer to choose wheather to purge or merge the message.
Retry Count
After Each Retry and publishing to the retry topic , a Header shall be added to the message to indicate the retry count and be incremented with each retry . This Retry Count should be configurable from the Client before sending.
Delay Backoff Time
The Delay between each retry should be incremental meaning that there should be a configurable time that increases incrementally to give a chance for the service if it has a transient error to revert back to its normal state , hence not spamming the service and getting resulting errors because the service didn't have enough time to return back to its normal working state
Nice to Have
Errors Classification , meaning that some errors are not transient and are permanent which may indicate a problem or a bug that needs to be fixed , in that case it doesn't make sense to retry these types of errors and it is better to send directly to the DLQ (Dead Letter Queue) to be inspected manually and choosing to purge or merge the message
Advantages
- Unblocked batch processing
- Decoupling
- Observability
Disadvantages | Trade-offs
- Handling Extra Topics
- Event Listeners Need to be added in each service to handle the retry topics and DLQ topics.
- Doesn't Guarantee that messages to be recieved with the same order that they were originally sent.
Code Usage
let's now check how can we configure and use all these stuff that we discussed in Java Spring Boot.
Retryable Topic:
1@RetryableTopic(2 attempts = "${com.example.stream.event1.events.kafka.retries.config}",3 backoff = @Backoff(delayExpression = "${com.example.stream.event1.events.kafka.retries.delay}"),4 fixedDelayTopicStrategy = FixedDelayStrategy.SINGLE_TOPIC,5 dltStrategy = DltStrategy.FAIL_ON_ERROR6 include = {NotSupportedException.class}7)8@KafkaListener(9 groupId = "${com.example.stream.event1.events.kafka.group.id}",10 clientIdPrefix = "${com.example.stream.event1.consumer.id}",11 topics = {12 "${com.example.stream.event1.events.kafka.topic.event1}"13 },14 containerFactory = EventKafkaConsumerConfig.KAFKA_LISTENER_FACTORY_BEAN_NAME15)16public void listen(17 @Payload @Valid final MessageResponse messageResponse,18 @Header(KafkaHeaders.GROUP_ID) final String groupId,19 @Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) final String key,20 @Header(KafkaHeaders.RECEIVED_PARTITION_ID) final int partition,21 @Header(KafkaHeaders.CONSUMER) final KafkaConsumer<String, MessageResponse> consumer,22 @Header(KafkaHeaders.RECEIVED_TOPIC) final String topic,23 @Header(KafkaHeaders.RECEIVED_TIMESTAMP) final long timestamp,24 @Header(KafkaHeaders.OFFSET) final long offset,25 Acknowledgment acknowledgment26) {27 // do something with the message2829}DLQ Hanlder for failed messages :
1@DltHandler2public void handleFailedMessage(3 @Payload @Valid MessageResponse messageResponse,4 @Header(KafkaHeaders.GROUP_ID) final String groupId,5 @Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) final String key,6 @Header(KafkaHeaders.RECEIVED_PARTITION_ID) final int partition,7 @Header(KafkaHeaders.RECEIVED_TOPIC) final String topic,8 @Header(KafkaHeaders.CONSUMER) KafkaConsumer<String, MessageResponse> consumer,9 @Header(KafkaHeaders.RECEIVED_TIMESTAMP) final long timestamp,10 @Header(KafkaHeaders.OFFSET) final long offset11) {12 //handle failed messages1314}Reference : Kafka Error Handling Patterns
ARIGATO GOZAIMASU ありがと ございます