The Outbox Pattern .. Road to Resiliency
— Software, Data, Backend, Architecture, Microservices — 6 min read
After reading the first chapter of Designing Data Intensive Applications i came to the realization that one of the main pillars of writing good software is Reliability and must be considered in the future when am developing. When you write software you should make sure that your software is tolerant to Human, Hardware ,Network or Software errors.
In Microservices it is likely that you can face a bunch of those errors and if you are unfortunate then they might happen at the same time so it should be a priority to prepare your Application and services for such errors.
One of the common usecases seen today is maybe after your application is saving/updating some data it needs to notify another service/s to complete the flow of the usecase.
But a lot can go wrong in this simple process 🤔 let's have a look at the possible failure scenarios:
- Saving / updating into the database can fail.
- Broker or Message Queue that notifies the other services might be down.
- Networking issues when communicating with the Message Queue.
What are the implications of these kinds of Scenarios?
Are We able to recover from such scenarios ?
Let's first have a thought about the impilcations:
When the database is not responding or having an issue , means that a customer couldn't place an order for example and a developer might dodge this type of issue by implementing a transaction , make the data saving "Atomic" either it is saved or not , if the database is down then the transaction can be rolled back and return back an error to the client? Easy Right? 🧠
If the broker is down or there are transient network error while communicating with the broker is going to result into a data incosistency where an Order might have been placed but the the other service might not have been notified by this action .
A developer might implement status as "PENDING" for example and if there is a failure with Message Queue can save to a table with failed messages and let a CronJob pick the failed messages records and send to Message Queue one by one , this might fit the usecase if the traffic is small to meduim but if it is large then this solution is not scalable and resource wasteful because of the nature cronjobs and most importantly not "Near Real Time"
Enter The Transactional Outbox Pattern:
Usecase Order Placement:
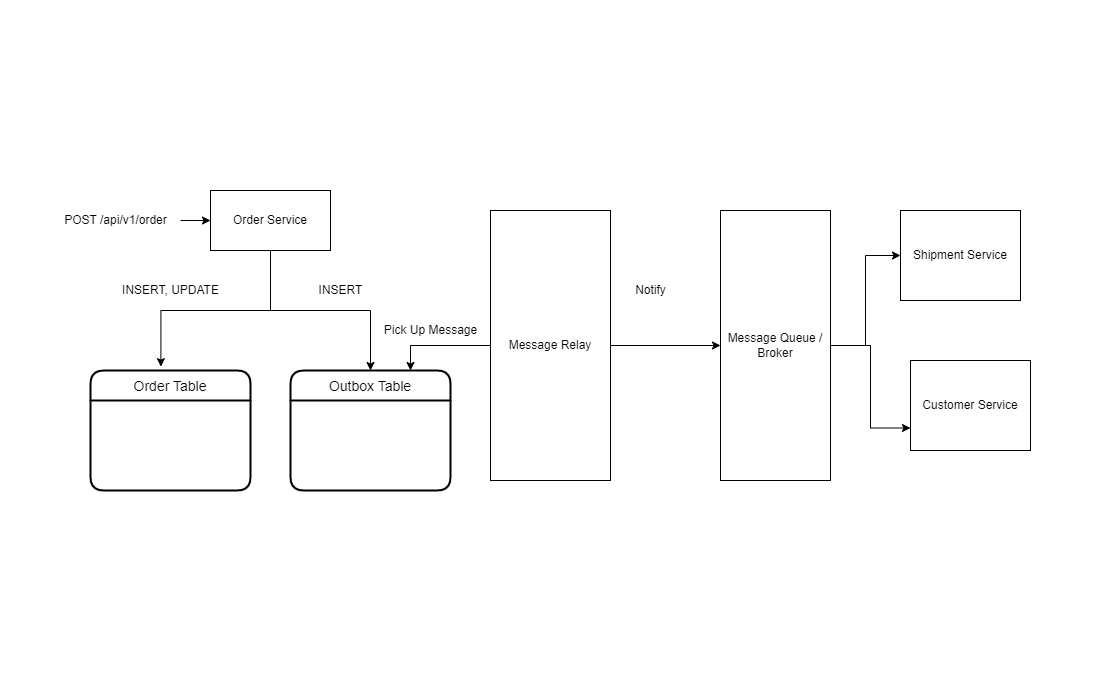
As seen from this diagram a customer makes an order goes to '/api/v1/order' to create an order. Notice that we are going to save 2 entries one in the order table and the other on the outbox table.
a message relay service is going to be listening for inserts in the outbox table , construct the payload and send to the message broker / Queue. The message queue on the other hand is going to notify the intersted services namely the customer and shipment service.
Now you are asking what is the beinfit 🤔 ? We just created an extra record for what now ? 🤔 and here is the trick , the message relay service listens to WAL known as the Write Ahead Log of the database. Each Database has a Write Ahead log whenever an insert , update , delete actions happen it saves the log history of those actions in the WAL which means we don't care about the record itself we care about the history it created so we can delete the record after and infact we are going to do that when we get to the implementation of this pattern.
Now let's get our hands dirty and implement these stuff and see how it works.
Enter a CDC implementation (Change Data Capture) :
Prerequisites
- Docker Compose
- Debezium
- Kafka as the MQ
- Postgresql as the database.
- Kafka Connect
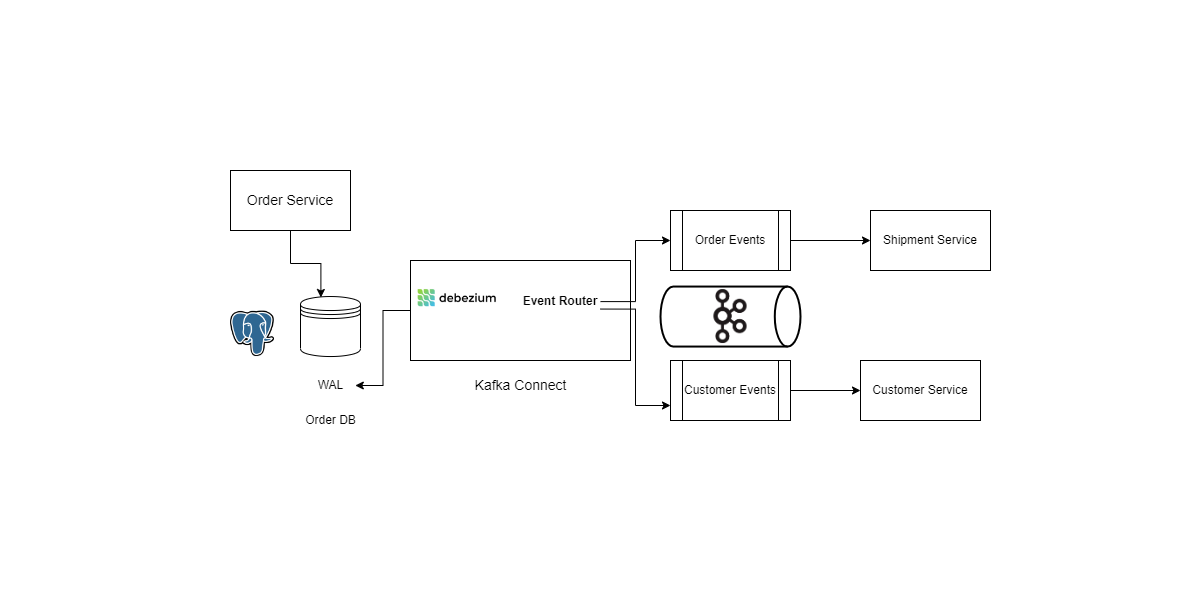
Let's Start explianing , we are going to create our services using docker compose and remember the Architecture above ? Well Debezium is a connector on top of kafka connect which is going to be our Message Relay service which is going to listen to the WAL of our Database.
Kafka is a Well Known Message Queue.
Log-based Change Data Capture (CDC) is a great fit for capturing new entries in the outbox table and stream them to Apache Kafka. As opposed to any polling-based approach, event capture happens with a very low overhead in near-realtime. Debezium comes with CDC connectors for several databases such as MySQL, Postgres and SQL Server. The following example will use the Debezium connector for Postgres.
Here is our updated Architecture:
Now let's Create a Docker-Compose file that will contain all our services :
1version: '3.7'23services:4 postgres:5 image: debezium/postgres:106 container_name: postgres7 networks:8 - kafka-network9 environment:10 POSTGRES_PASSWORD: admin11 POSTGRES_USER: admin-user12 ports:13 - 5432:54321415 zookeeper:16 image: confluentinc/cp-zookeeper:latest17 container_name: zookeeper18 networks:19 - kafka-network20 ports:21 - 2181:218122 environment:23 ZOOKEEPER_CLIENT_PORT: 218124 ZOOKEEPER_TICK_TIME: 20002526 kafka:27 image: confluentinc/cp-kafka:latest28 container_name: kafka29 networks:30 - kafka-network31 depends_on:32 - zookeeper33 ports:34 - 9092:909235 environment:36 KAFKA_ZOOKEEPER_CONNECT: zookeeper:218137 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:909238 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT39 KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT40 KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 141 KAFKA_LOG_CLEANER_DELETE_RETENTION_MS: 500042 KAFKA_BROKER_ID: 143 KAFKA_MIN_INSYNC_REPLICAS: 14445 connector:46 image: debezium/connect:latest47 container_name: kafka_connect_with_debezium48 networks:49 - kafka-network50 ports:51 - '8083:8083'52 environment:53 GROUP_ID: 154 CONFIG_STORAGE_TOPIC: my_connect_configs55 OFFSET_STORAGE_TOPIC: my_connect_offsets56 BOOTSTRAP_SERVERS: kafka:2909257 depends_on:58 - zookeeper59 - kafka6061networks:62 kafka-network:63 driver: bridgeThis will Create all our prerequisites above
now docker-compose up it is going to pull the images down and build the containers for you.
Next thing we will need to create a database inisde the postgres container you can create any name you want maybe Order_Outbox
but should have the following Schema :
1Column | Type | Modifiers2--------------+------------------------+-----------3id | uuid | not null4aggregatetype | character varying(255) | not null5aggregateid | character varying(255) | not null6type | character varying(255) | not null7payload | jsonb | not nullLet's Explain the table a little bit to make it clear:
id: unique id of each message; can be used by consumers to detect any duplicate events, e.g. when restarting to read messages after a failure. Generated when creating a new event.
aggregatetype: the type of the aggregate root to which a given event is related; the idea being, leaning on the same concept of domain-driven design, that exported events should refer to an aggregate. This value will be used to route events to corresponding topics in Kafka, so there’d be a topic for all events related to purchase orders, one topic for all customer-related events etc. Note that also events pertaining to a child entity contained within one such aggregate should use that same type. So e.g. an event representing the cancelation of an individual order line (which is part of the purchase order aggregate) should also use the type of its aggregate root, "order", ensuring that also this event will go into the "order" Kafka topic.
aggregateid: the id of the aggregate root that is affected by a given event; this could for instance be the id of a purchase order or a customer id; Similar to the aggregate type, events pertaining to a sub-entity contained within an aggregate should use the id of the containing aggregate root, e.g. the purchase order id for an order line cancelation event. This id will be used as the key for Kafka messages later on. That way, all events pertaining to one aggregate root or any of its contained sub-entities will go into the same partition of that Kafka topic, which ensures that consumers of that topic will consume all the events related to one and the same aggregate in the exact order as they were produced.
type: the type of event, e.g. "Order Created" or "Order Line Canceled". Allows consumers to trigger suitable event handlers.
payload: a JSON structure with the actual event contents, e.g. containing a purchase order, information about the purchaser, contained order lines, their price etc.
now Let's Configure the connector itself :
POST http://localhost:8083/connectors/
Payload :
1{2 "name": "your_connector_name",3 "config": {4 "connector.class": "io.debezium.connector.postgresql.PostgresConnector",5 "tasks.max": "1",6 "topic.creation.enable": "true",7 "topic.prefix": "order",8 "database.hostname": "postgres",9 "database.port": "5432",10 "database.user": "admin-user",11 "database.password": "admin",12 "database.dbname": "postgres",13 "database.server.name": "postgres",14 "topic.creation.default.replication.factor": 1,15 "topic.creation.default.partitions": 10,16 "key.converter": "org.apache.kafka.connect.storage.StringConverter",17 "key.converter.schemas.enable": "false",18 "value.converter": "org.apache.kafka.connect.json.JsonConverter",19 "value.converter.schemas.enable": "false",20 "include.schema.changes": "false"21 }22}Now let's Make sure everything is working fine : GET http://localhost:8083/connectors/your_connector_name/status
Response should be :
1{2 "name": "your_connector_name",3 "connector": {4 "state": "RUNNING",5 "worker_id": "172.20.0.5:8083"6 },7 "tasks": [8 {9 "id": 0,10 "state": "RUNNING",11 "worker_id": "172.20.0.5:8083"12 }13 ],14 "type": "source"15}Now lets install a VS Code Extension open extensions and search kafka and install this one:
Now let's connect to our cluster :
Hit save , now let's connect to postgres container via your fav. Client am going to use Dbeaver:
let's now insert some data inside the Order_Outbox table
1INSERT INTO public.Order_Outbox2(id, aggregateid, aggregatetype,type,payload)3VALUES('123', '1234', 'shipment',"order created",'{"test:"hello"}');Now you should see in the vscode extension a topic created with the name we specified in the above config.
you can right click and create a consumer in vscode.
now try to insert again it will appear in vscode consumer .
But How did we solve the old problems of kafka being down and we added another component which is Kafka Connect which may fail as well?
Here is the beauty of it from the documentation:
Kafka becomes unavailable As the connector generates change events, the Kafka Connect framework records those events in Kafka by using the Kafka producer API. Periodically, at a frequency that you specify in the Kafka Connect configuration, Kafka Connect records the latest offset that appears in those change events. If the Kafka brokers become unavailable, the Kafka Connect process that is running the connectors repeatedly tries to reconnect to the Kafka brokers. In other words, the connector tasks pause until a connection can be re-established, at which point the connectors resume exactly where they left off.
Connector is stopped for a duration If the connector is gracefully stopped, the database can continue to be used. Any changes are recorded in the PostgreSQL WAL. When the connector restarts, it resumes streaming changes where it left off. That is, it generates change event records for all database changes that were made while the connector was stopped.
you can find the docker-compose file here Github Repo
Reference : Transactional Outbox Pattern
ARIGATO GOZAIMASU ありがと ございます